引言
作为一个重度 AI 用户,我每天通过各类 coding agent 与十几个 AI 平台打交道:Germanna、CodeX、GitLab Copilot、智谱 AI、MiniMax、千问、火山方舟等等。每个平台都提供 API 额度,但分散管理成了噩梦。
问题不是总额度不够,而是分配不均。我经常在任务中途遇到某个平台的 rate limit,而其他平台的额度却没怎么用。在不同设备之间切换不同的 base URL、API key 和认证方式既繁琐又容易出错。
我的解决方案?自建 LLM Gateway 统一管理所有 API key,通过 Tailscale 暴露给所有设备,实现智能路由、负载均衡和资源池化。
为什么选择 New API?
我花了相当多时间评估不同的 gateway 方案。以下是我的考虑:
| 方案 | 特点 | 为什么不选 |
|---|---|---|
| LiteLLM | Python 方案,provider 支持广 | 相对重,需要 Python 环境 |
| one-api | Go 方案,功能最完整 | 商业功能多,对个人来说复杂 |
| uni-api | 轻量级,纯配置文件 | 功能相对简单 |
| New API | one-api 二次开发,现代化 UI | 更适合我的个人配置 |
LiteLLM 很适合 Python 重度工作流,provider 支持也很广。但它需要管理 Python 环境,对于我的使用场景来说感觉有点重。
one-api 是功能最完整的方案,代码库成熟。但它包含很多面向商业的功能,对我来说用不上,导致 UI 对个人用户来说显得杂乱。
uni-api 采取极简主义方式,纯配置文件无 UI。虽然优雅,但缺乏我想要的 token 使用可视化分析功能。
New API 对我来说是比较合适的折中。它基于 one-api 二次开发,界面更清爽,支持 Midjourney 等额外服务,也提供 token 统计和费用分析,同时还能保持简单的 Docker 部署。
核心收益
智能路由
Gateway 最有用的地方是智能路由。当某个平台 rate limit 时,gateway 自动切换到备用 provider,coding agent 无感知,不中断工作流。
实际工作原理是这样的:我为同一个逻辑模型配置多个 channel(provider 连接)。当我发送请求到 claude-sonnet 时,gateway 会在智谱 AI、MiniMax、千问等 channel 之间路由。如果智谱返回 rate limit 错误,gateway 会在几毫秒内自动用 MiniMax 重试。
这一切都是透明的。我的 coding agent 不需要知道后面发生了什么,只会看到一个成功的响应。
负载均衡
除了故障转移,gateway 还使用加权随机选择在多个平台之间分配并发请求。这避免了单点限流导致任务卡住。
flowchart LR
A[单个请求] --> B[Gateway]
B --> C[Provider 1]
B --> D[Provider 2]
B --> E[Provider 3]
C --> F[响应]
D --> F
E --> F
权重是可配置的。我给额度更大或价格更优的 provider 分配更高权重,确保资源最优利用。
资源池化
这才是真正的魔法所在。所有平台的 quota 变成一个”大池子”,不再浪费任何一家的剩余额度。
之前:每家都”差点意思”,经常这家用完那家还剩很多。我不停地监控仪表板,在某个平台接近限额时手动切换 provider。
之后:所有额度一起用,哪个便宜/有额度就走哪个。gateway 把我所有的 API key 当作一个资源池,“榨干每一个 token”。
成本优化是可以直接观察到的。我可以针对给定模型通过价格更合适的 provider 路由流量,gateway 会处理其余的事情。
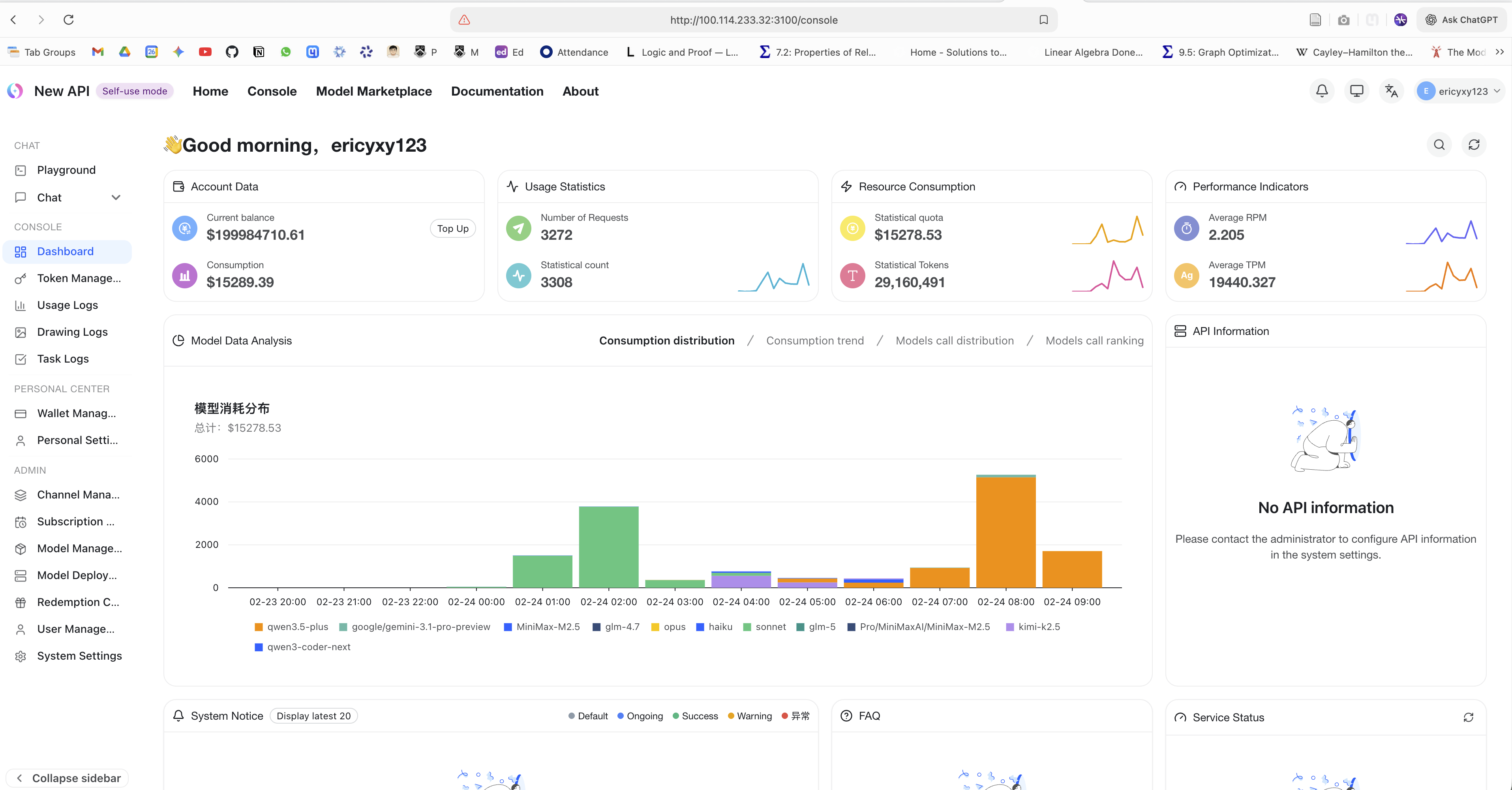
New API 仪表板展示了请求量、token 使用量与模型消费分布,便于观察资源池化后的整体使用情况。
统一访问
从客户端角度来看,设置足够简单:一个 base URL。Claude Code、Cursor、Cline 等工具都指向 http://100.100.1.100:3000/v1(我 gateway 的 Tailscale IP)。在后台,我可以切换 model provider、调整路由权重或添加新平台,而无需触碰客户端配置。
通过 Tailscale,所有设备都访问同一个 gateway。我的 MacBook、PC 和手机都使用同一个 endpoint,无论它们身在何处。
架构设计
系统架构概览
架构由三层组成:客户端、gateway 和 provider。
graph TB
subgraph "客户端设备 & 应用"
A1[MacBook - Claude Code]
A2[MacBook - Cursor]
A3[MacBook - Cline/Roo Code]
B1[PC - VS Code + Copilot]
B2[PC - Germanna]
C1[手机 - Cherry Studio]
C2[手机 - 其他 AI 应用]
end
subgraph "Tailscale Mesh 网络"
D[Tailscale P2P 网络<br/>100.100.1.x]
end
subgraph "Gateway 服务器"
E[New API Gateway]
F[Token 分析仪表板]
G[负载均衡 & 路由器]
H[(数据库<br/>PostgreSQL/SQLite)]
I[(Redis 缓存)]
end
subgraph "AI Providers (10+ 平台)"
J1[智谱 AI]
J2[MiniMax]
J3[千问]
J4[火山方舟]
J5[Germanna]
J6[CodeX]
J7[GitLab Copilot]
J8[其他平台...]
end
A1 --> D
A2 --> D
A3 --> D
B1 --> D
B2 --> D
C1 --> D
C2 --> D
D --> E
E --> F
E --> G
E --> H
E --> I
G --> J1
G --> J2
G --> J3
G --> J4
G --> J5
G --> J6
G --> J7
G --> J8
客户端层:我所有的 coding agent 和 AI 应用,包括 MacBook 上的 Claude Code、Cursor、Cline/Roo Code,PC 上的 VS Code + Copilot、Germanna,以及手机上的 Cherry Studio 和其他 AI 应用。
Gateway 层:New API 服务器处理路由、负载均衡和分析。PostgreSQL/SQLite 存储使用数据,Redis 提供低延迟路由决策的缓存。
Provider 层:10+ AI 平台,包括智谱、MiniMax、千问、火山方舟、Germanna、CodeX、GitLab Copilot 等。
请求处理流程
了解请求如何在系统中流动有助于理解背后发生的魔法:
sequenceDiagram
participant Client as Coding Agent
participant GW as New API Gateway
participant Router as Router
participant XF as Transformer
participant Provider as AI Provider
Client->>GW: POST /v1/chat/completions<br/>(OpenAI 格式)
GW->>Router: 路由到 channel
Router->>Router: 加权随机 /<br/>故障转移选择
Router->>XF: 转换格式
XF->>XF: OpenAI → Provider 格式<br/>(max_tokens, tools 等)
XF->>Provider: 转发请求
Provider-->>XF: 响应
XF-->>XF: 标准化响应
XF-->>GW: 转换回 OpenAI 格式
GW-->>Client: 响应 (含重试逻辑)
- 客户端请求:你的 coding agent 发送标准 OpenAI 格式请求到 gateway。
- 路由:路由器根据权重、可用性和重试逻辑选择 channel。
- 转换:转换器将请求转换为 provider 期望的格式。
- 转发:请求发送到实际的 provider API。
- 响应标准化:响应被转换回 OpenAI 格式。
- 返回:你的 agent 收到响应,完全不知道背后的复杂性。
智能路由策略
路由策略结合了加权随机选择和自动故障转移:
flowchart LR
A[客户端请求] --> B{模型映射}
B -->|claude-sonnet| C[Channel 池]
C --> D[Channel 1: 智谱<br/>权重:30%]
C --> E[Channel 2: MiniMax<br/>权重:40%]
C --> F[Channel 3: 千问<br/>权重:30%]
D --> G{成功?}
E --> G
F --> G
G -->|是 | H[返回响应]
G -->|否:Rate Limit| I[重试下一 Channel]
G -->|否:格式错误 | J[返回错误]
I --> D
I --> E
I --> F
当 claude-sonnet 请求到达时,它进入包含三个 provider 的 channel 池。路由器执行加权随机选择:MiniMax 获得 40% 的流量,智谱和千问各获得 30%。如果选中的 channel 因 rate limit 失败,路由器自动重试下一个可用 channel。
参数转换原理
不同的 LLM provider 使用不同的参数名称和格式。gateway 透明地处理这些转换:
flowchart TD
subgraph Client["客户端请求"]
A["POST /v1/chat/completions<br/>(OpenAI 格式)<br/>- temperature<br/>- max_tokens<br/>- top_p<br/>- tools"]
end
subgraph Gateway["New API Gateway"]
B["模型映射层<br/>- 路由到 channels<br/>- 参数标准化"]
C["转换引擎<br/>- 格式转换<br/>- 消息适配<br/>- 流式协议处理"]
end
subgraph Providers["AI Providers"]
D1["智谱 AI<br/>(OpenAI 兼容)"]
D2["MiniMax<br/>(OpenAI 兼容)"]
D3["Anthropic<br/>(Claude 格式)"]
D4["Gemini<br/>(自定义格式)"]
end
A --> B
B --> C
C --> D1
C --> D2
C --> D3
C --> D4
常见参数映射:
| 客户端参数 | 智谱/MiniMax | Anthropic | Gemini | 说明 |
|---|---|---|---|---|
max_tokens | max_tokens | max_tokens | maxOutputTokens | 默认值差异大 |
temperature | temperature | temperature | temperature | 某些不支持 0 |
top_p | top_p | top_p | topP | 广泛支持 |
stream | stream | stream | 不支持 | 流式协议差异 |
tools | functions | tools | tools | 格式不完全兼容 |
转换自动发生。你发送 OpenAI 格式请求,gateway 负责与每个 provider 通信。
Tailscale Mesh 组网
Tailscale 在所有设备之间创建安全的 mesh 网络,无需复杂的网络设置:
graph LR
subgraph "你的网络"
A[MacBook<br/>100.100.1.1]
B[PC<br/>100.100.1.2]
C[手机<br/>100.100.1.3]
D[Gateway 服务器<br/>100.100.1.100]
end
A <-.Tailscale P2P.-> B
A <-.Tailscale P2P.-> C
A <-.Tailscale P2P.-> D
B <-.Tailscale P2P.-> C
B <-.Tailscale P2P.-> D
C <-.Tailscale P2P.-> D
style D fill:#4CAF50,color:#fff
每个设备获得一个 100.100.1.x 范围内的 Tailscale IP。gateway 服务器运行在 100.100.1.100。其他设备通过 P2P 直接连接,不需要 exit node。这能保持低延迟和高带宽。
部署步骤
Docker Compose 配置
New API 提供官方 Docker Compose 模板。以下是基础配置:
version: '3'services: new-api: image: calciumion/new-api:latest container_name: new-api restart: always environment: - SESSION_SECRET=your_session_secret - SQL_DSN=/data/new-api.db - REDIS_CONN_STRING=redis://redis:6379 volumes: - ./data:/data ports: - "3000:3000" depends_on: - redis
redis: image: redis:alpine container_name: new-api-redis restart: always volumes: - ./redis-data:/data关键配置点:
SESSION_SECRET:会话管理必需。生产环境请生成随机字符串。SQL_DSN:数据库连接。默认使用 SQLite(/data/new-api.db),但多实例部署可切换到 PostgreSQL。REDIS_CONN_STRING:Redis 用于缓存。提高负载下的路由性能。
部署命令:
docker-compose up -dTailscale 配置
设置 Tailscale 很简单:
- 在所有设备上安装 Tailscale(MacBook、PC、服务器、手机)
- 所有设备使用同一账号登录
- 记录 gateway 服务器设备的 Tailscale IP
- 配置防火墙规则允许 3000 端口(或自定义端口)的入站连接
不需要 exit node,因为我们使用 P2P mesh 组网。Tailscale 自动处理 NAT 穿透。
添加 API Channel
Gateway 运行后:
- 访问仪表板:导航到
http://<gateway-tailscale-ip>:3000 - 首次登录时创建管理员账号
- 导航到 Channels → Add Channel
- 选择 provider 类型(OpenAI Compatible、Anthropic 等)
- 为每个 provider 输入 API key 和 base URL
- 配置模型映射定义每个 channel 提供哪些 upstream 模型
对于模型映射,你可以配置多个 channel 服务同一个逻辑模型。例如,三个 channel(智谱、MiniMax、千问)都可以服务 claude-sonnet,实现前面描述的智能路由。
踩坑与解决方案
Tools / Function Calling 兼容性问题
这是我在设置过程中遇到的主要问题。
问题场景:
当智能路由将一个模型字段(如 claude-sonnet)映射到多个 provider channel 时,不同 provider 对 tools / function_calling 的支持程度不同,导致 coding agent 的请求在某些 channel 失败。
Cline 和 Roo Code 等 coding agent 严重依赖 function calling 来执行文件操作、终端命令和搜索功能。当 gateway 将带 tools 的请求路由到不支持相同格式的 provider 时,请求失败。
具体表现:
| 问题类型 | 描述 | 示例 |
|---|---|---|
| 格式不兼容 | OpenAI functions vs Anthropic tools | 参数结构差异 |
| 参数不支持 | tool_choice 的 auto/required 选项 | 某些模型只支持 none |
| 响应解析差异 | tool_calls 返回结构不同 | JSON string vs parsed object |
| 默认值差异 | max_tokens 默认值不同 | Ollama 128 vs vLLM 16 |
解决方案:
-
对于需要 tool calling 的场景,固定使用单一 provider。配置你的 coding agent 使用专用的模型 endpoint,映射到单一可靠的 provider(比如只用智谱或只用 MiniMax)。
-
在 New API 中为不同功能配置不同的模型路由规则。创建独立的逻辑模型:
claude-sonnet-chat→ 路由到多个 provider(仅聊天,无 tools)claude-sonnet-coding→ 路由到单一 provider(支持 tools)
-
或者:创建独立的”coding”和”chat”路由。这是我最终采用的方案。所有 tool-calling 请求通过”coding”路由到固定 provider,而普通聊天请求使用池化路由。
Tailscale 组网注意事项
有几点需要注意:
- 使用 P2P mesh 网络直接在设备间通信,不需要 exit node。这保持低延迟。
- 确保所有设备都能访问 gateway 服务器设备。如果 Tailscale 回退到中继模式(因为直接 P2P 不可行),性能会受影响。
- 根据需要配置防火墙/端口转发。gateway 服务器需要在其 Tailscale IP 上接受入站连接。
总结
这个 gateway 解决的是一个很具体的问题:API access 不再散落在不同的 key、base URL 和 provider dashboard 里。统一访问、路由和资源池化减少了以前经常打断 coding session 的 rate limit。
第一个实际信号很普通,但很有用:比较密集的 coding session 里,我不需要再停下来手动切 provider。token 分析仪表板也让我看清哪些 provider 用得少,后面就更容易重新分配支出。
适合人群:
- 管理多个平台 API key 的重度 AI 用户
- 经常被单家 provider rate limit 困扰的开发者
- 想要集中 token 使用分析的用户
- 需要在设备间共享 AI 基础设施的团队
可能不需要的人群:
- 只有单一 provider 的轻度用户
- 对手动切换 provider 感到舒适的人
- 没有多设备访问需求的用户
这套东西需要一些初始投入,大概一个晚上用来部署和配置。对我的工作流来说,主要收益是可靠性:少一些 provider 切换,少一些被 rate limit 打断的 coding session,也更容易看清 token 使用情况。
讨论