Introduction
As a heavy AI user, I interact with over a dozen AI platforms daily through various coding agents: Germanna, CodeX, GitLab Copilot, Zhipu AI, MiniMax, Qwen, Volcano Ark, and more. Each platform provides API quotas, but managing them across separate accounts became a mess.
The problem was distribution, not total quota. I would hit rate limits on one platform mid-task while others sat underused. Switching between different base URLs, API keys, and authentication methods across my devices was tedious and error-prone.
I ended up building a self-hosted LLM gateway: one place to manage API keys, route requests, and expose the same endpoint to my devices through Tailscale.
Why New API?
I spent considerable time evaluating different gateway solutions. Here’s what I considered:
| Solution | Characteristics | Why Not |
|---|---|---|
| LiteLLM | Python-based, broad provider support | Relatively heavy, requires Python environment |
| one-api | Go-based, most complete features | Too many commercial features, complex for personal use |
| uni-api | Lightweight, config-file only | Relatively simple functionality |
| New API | Fork of one-api with modern UI | Best fit for my personal setup |
LiteLLM fits Python-heavy workflows and has extensive provider support. However, it requires managing a Python environment and feels heavier than needed for my use case.
one-api is the most feature-complete option with a mature codebase. But it includes many commercial-oriented features I don’t need, making the UI feel cluttered for personal use.
uni-api takes a minimalist approach with pure configuration files and no UI. While elegant, it lacks the visual analytics I wanted for tracking token usage across providers.
New API was the most practical middle ground for me. It is a fork of one-api with a cleaner interface, supports extra services like Midjourney, and provides token and cost analytics while keeping Docker deployment simple.
Key Benefits
Intelligent Routing
The main reason I kept the gateway is routing. When one platform hits rate limits, the gateway can switch to a backup provider without interrupting the coding agent workflow.
Here’s how it works in practice: I configure multiple channels (provider connections) for the same logical model. When I send a request to claude-sonnet, the gateway routes it across configured channels such as Zhipu AI, MiniMax, and Qwen. If Zhipu returns a rate limit error, the gateway retries with MiniMax within milliseconds.
This happens transparently. My coding agent only sees a successful response.
Load Balancing
Beyond failover, the gateway distributes concurrent requests across multiple platforms using weighted random selection. This prevents any single point of rate limiting from blocking tasks.
flowchart LR
A[Single Request] --> B[Gateway]
B --> C[Provider 1]
B --> D[Provider 2]
B --> E[Provider 3]
C --> F[Response]
D --> F
E --> F
The weighting is configurable. I assign higher weights to providers with larger quotas or better pricing, ensuring optimal resource utilization.
Resource Pooling
This is where the real magic happens. All platform quotas merge into one “big pool”. No more wasted unused quotas from any provider.
Before: Each platform was “almost enough” but often one ran out while others had plenty remaining. I’d constantly monitor dashboards, manually switching providers when one approached its limit.
After: All quotas work together, using whichever is cheaper or has available capacity. The gateway treats all my API keys as a single resource pool, “squeezing every token dry.”
The cost optimization is measurable. I can route traffic through whichever provider offers the best price for a given model, and the gateway handles the rest.
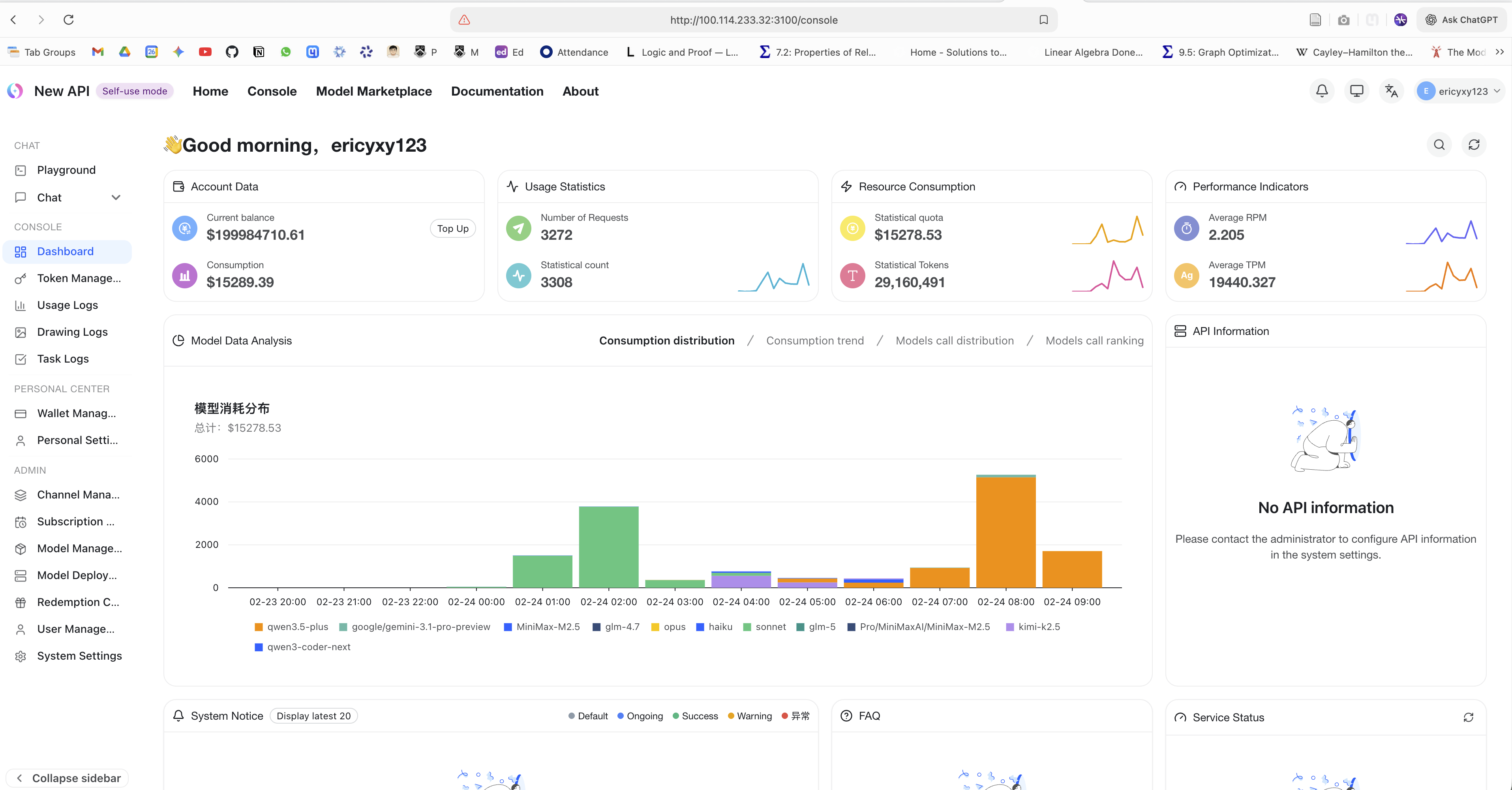
New API dashboard showing requests, token usage, and model consumption distribution from the pooled gateway setup.
Unified Access
From a client perspective, the setup is simple: one base URL. Claude Code, Cursor, Cline, and other tools all point to http://100.100.1.100:3000/v1 (my gateway’s Tailscale IP). Behind the scenes, I can switch model providers, adjust routing weights, or add new platforms without touching client configurations.
With Tailscale, all devices access the same gateway. My MacBook, PC, and phone all use the same endpoint, regardless of where they are.
Architecture
System Overview
The architecture consists of three layers: clients, gateway, and providers.
graph TB
subgraph "Client Devices & Apps"
A1[MacBook - Claude Code]
A2[MacBook - Cursor]
A3[MacBook - Cline/Roo Code]
B1[PC - VS Code + Copilot]
B2[PC - Germanna]
C1[Mobile - Cherry Studio]
C2[Mobile - Other AI Apps]
end
subgraph "Tailscale Mesh Network"
D[Tailscale P2P Network<br/>100.100.1.x]
end
subgraph "Gateway Server"
E[New API Gateway]
F[Token Analytics Dashboard]
G[Load Balancer & Router]
H[(Database<br/>PostgreSQL/SQLite)]
I[(Redis Cache)]
end
subgraph "AI Providers (10+ Platforms)"
J1[智谱 AI]
J2[MiniMax]
J3[千问]
J4[火山方舟]
J5[Germanna]
J6[CodeX]
J7[GitLab Copilot]
J8[其他平台...]
end
A1 --> D
A2 --> D
A3 --> D
B1 --> D
B2 --> D
C1 --> D
C2 --> D
D --> E
E --> F
E --> G
E --> H
E --> I
G --> J1
G --> J2
G --> J3
G --> J4
G --> J5
G --> J6
G --> J7
G --> J8
Client Layer: All my coding agents and AI apps: Claude Code, Cursor, Cline/Roo Code on MacBook; VS Code + Copilot and Germanna on PC; Cherry Studio and other AI apps on mobile.
Gateway Layer: The New API server handles routing, load balancing, and analytics. PostgreSQL/SQLite stores usage data, while Redis provides caching for low-latency routing decisions.
Provider Layer: 10+ AI platforms including Zhipu, MiniMax, Qwen, Volcano Ark, Germanna, CodeX, GitLab Copilot, and more.
Request Flow
Understanding how a request flows through the system helps explain the magic happening behind the scenes:
sequenceDiagram
participant Client as Coding Agent
participant GW as New API Gateway
participant Router as Router
participant XF as Transformer
participant Provider as AI Provider
Client->>GW: POST /v1/chat/completions<br/>(OpenAI format)
GW->>Router: Route to channel
Router->>Router: Weighted random /<br/>fallback selection
Router->>XF: Convert format
XF->>XF: OpenAI → Provider format<br/>(max_tokens, tools, etc.)
XF->>Provider: Forward request
Provider-->>XF: Response
XF-->>XF: Normalize response
XF-->>GW: Convert back to OpenAI format
GW-->>Client: Response (with retry logic)
- Client Request: Your coding agent sends a standard OpenAI-format request to the gateway.
- Routing: The router selects a channel based on weights, availability, and retry logic.
- Transformation: The transformer converts the request to the provider’s expected format.
- Forwarding: The request goes to the actual provider API.
- Response Normalization: The response is converted back to OpenAI format.
- Return: Your agent receives the response, unaware of the complexity behind it.
Intelligent Routing Strategy
The routing strategy combines weighted random selection with automatic failover:
flowchart LR
A[Client Request] --> B{Model Mapping}
B -->|claude-sonnet| C[Channel Pool]
C --> D[Channel 1: 智谱<br/>Weight: 30%]
C --> E[Channel 2: MiniMax<br/>Weight: 40%]
C --> F[Channel 3: 千问<br/>Weight: 30%]
D --> G{Success?}
E --> G
F --> G
G -->|Yes| H[Return Response]
G -->|No: Rate Limit| I[Retry Next Channel]
G -->|No: Format Error| J[Return Error]
I --> D
I --> E
I --> F
When a request for claude-sonnet arrives, it enters a channel pool containing three providers. The router performs weighted random selection: MiniMax gets 40% of traffic, while Zhipu and Qwen each get 30%. If the selected channel fails with a rate limit, the router automatically retries the next available channel.
Parameter Translation
Different LLM providers use different parameter names and formats. The gateway handles these translations transparently:
flowchart TD
subgraph Client["Client Request"]
A["POST /v1/chat/completions<br/>(OpenAI Format)<br/>- temperature<br/>- max_tokens<br/>- top_p<br/>- tools"]
end
subgraph Gateway["New API Gateway"]
B["Model Mapping Layer<br/>- Route to channels<br/>- Parameter normalization"]
C["Transformer Engine<br/>- Format conversion<br/>- Message adaptation<br/>- Streaming protocol"]
end
subgraph Providers["AI Providers"]
D1["智谱 AI<br/>(OpenAI Compatible)"]
D2["MiniMax<br/>(OpenAI Compatible)"]
D3["Anthropic<br/>(Claude Format)"]
D4["Gemini<br/>(Custom Format)"]
end
A --> B
B --> C
C --> D1
C --> D2
C --> D3
C --> D4
Common Parameter Mappings:
| Client Param | Zhipu/MiniMax | Anthropic | Gemini | Notes |
|---|---|---|---|---|
max_tokens | max_tokens | max_tokens | maxOutputTokens | Default values vary by provider |
temperature | temperature | temperature | temperature | Some models don’t support 0 |
top_p | top_p | top_p | topP | Widely supported |
stream | stream | stream | Not supported | Streaming protocol differences |
tools | functions | tools | tools | Format incompatibilities |
The translation happens automatically. You send OpenAI-format requests, and the gateway figures out how to talk to each provider.
Tailscale Mesh Network
Tailscale creates a secure mesh network between all my devices without requiring complex networking setup:
graph LR
subgraph "Your Network"
A[MacBook<br/>100.100.1.1]
B[PC<br/>100.100.1.2]
C[Mobile<br/>100.100.1.3]
D[Gateway Server<br/>100.100.1.100]
end
A <-.Tailscale P2P.-> B
A <-.Tailscale P2P.-> C
A <-.Tailscale P2P.-> D
B <-.Tailscale P2P.-> C
B <-.Tailscale P2P.-> D
C <-.Tailscale P2P.-> D
style D fill:#4CAF50,color:#fff
Each device gets a Tailscale IP in the 100.100.1.x range. The gateway server (where New API runs) sits at 100.100.1.100. Other devices connect directly via P2P, so no exit node is required. This keeps latency low and bandwidth high.
Deployment Steps
Docker Compose Configuration
New API provides an official Docker Compose template. Here’s the basic setup:
version: '3'services: new-api: image: calciumion/new-api:latest container_name: new-api restart: always environment: - SESSION_SECRET=your_session_secret - SQL_DSN=/data/new-api.db - REDIS_CONN_STRING=redis://redis:6379 volumes: - ./data:/data ports: - "3000:3000" depends_on: - redis
redis: image: redis:alpine container_name: new-api-redis restart: always volumes: - ./redis-data:/dataKey Configuration Points:
SESSION_SECRET: Required for session management. Generate a random string for production.SQL_DSN: Database connection. Uses SQLite by default (/data/new-api.db), but you can switch to PostgreSQL for multi-instance deployments.REDIS_CONN_STRING: Redis for caching. Improves routing performance under load.
Deploy with:
docker-compose up -dTailscale Setup
Setting up Tailscale is straightforward:
- Install Tailscale on all devices (MacBook, PC, server, mobile)
- Log in with the same account on all devices
- Note the Tailscale IP of the gateway server device
- Configure firewall rules to allow incoming connections on port 3000 (or your custom port)
No exit node is needed since we’re using P2P mesh networking. Tailscale handles NAT traversal automatically.
Adding API Channels
Once the gateway is running:
- Access the dashboard by navigating to
http://<gateway-tailscale-ip>:3000 - Create an admin account on first login
- Navigate to Channels → Add Channel
- Select provider type (OpenAI Compatible, Anthropic, etc.)
- Enter API key and base URL for each provider
- Configure model mappings to define which upstream models each channel provides
For model mappings, you can configure multiple channels to serve the same logical model. For instance, all three channels (Zhipu, MiniMax, Qwen) can serve claude-sonnet, enabling the intelligent routing described earlier.
Issues & Solutions
Tools / Function Calling Compatibility
This was the main issue I encountered during setup.
Problem Scenario:
When intelligent routing maps a single model field (e.g., claude-sonnet) to multiple provider channels, different providers have varying support for tools / function_calling, causing requests from coding agents to fail on certain channels.
Coding agents like Cline and Roo Code rely heavily on function calling for file operations, terminal commands, and search functionality. When the gateway routes a request with tools to a provider that doesn’t support the same format, the request fails.
Specific Issues:
| Issue Type | Description | Example |
|---|---|---|
| Format Incompatibility | OpenAI functions vs Anthropic tools | Parameter structure differences |
| Unsupported Parameters | tool_choice with auto/required options | Some models only support none |
| Response Parsing Differences | tool_calls return structure varies | JSON string vs parsed object |
| Default Value Differences | max_tokens defaults vary | Ollama 128 vs vLLM 16 |
Solutions:
-
For tool calling scenarios, use a fixed single provider. Configure your coding agent to use a dedicated model endpoint that maps to one reliable provider (e.g., only Zhipu or only MiniMax).
-
Configure different model routing rules in New API for different functionalities. Create separate logical models:
claude-sonnet-chat→ routed to multiple providers (chat-only, no tools)claude-sonnet-coding→ routed to single provider (supports tools)
-
Or: Create separate “coding” and “chat” routes. This is the approach I eventually adopted. All tool-calling requests go through a “coding” route with a fixed provider, while general chat requests use the pooled routing.
Tailscale Networking Notes
A few things to keep in mind:
- P2P mesh networking is used directly between devices, no exit node required. This keeps latency low.
- Ensure all devices can reach the gateway server device. If Tailscale falls back to relay mode (because direct P2P isn’t possible), performance will suffer.
- Configure firewall/port forwarding as needed. The gateway server needs to accept incoming connections on its Tailscale IP.
Conclusion
The gateway changed one specific part of my workflow: API access stopped being scattered across separate keys, base URLs, and provider dashboards. Unified access, routing, and pooling reduced the rate-limit interruptions that used to break coding sessions.
The first practical signal was boring but useful. During heavier coding sessions, I no longer had to stop and swap providers manually. The analytics dashboard also made underused providers visible, which gave me a better way to rebalance spending.
Who Should Consider This:
- Heavy AI users managing multiple platform API keys
- Developers experiencing frequent rate limits from single providers
- Anyone wanting centralized token usage analytics
- Teams needing shared AI infrastructure across devices
Who Might Skip It:
- Light users with a single provider
- Anyone comfortable with manual provider switching
- Those without multiple devices needing access
The setup takes some initial effort, roughly an evening for deployment and configuration. For my workflow, the payoff is reliability: fewer provider switches, fewer interrupted coding sessions, and a clearer view of token usage.
Discussion